热门
最新
点赞最多
评论最多
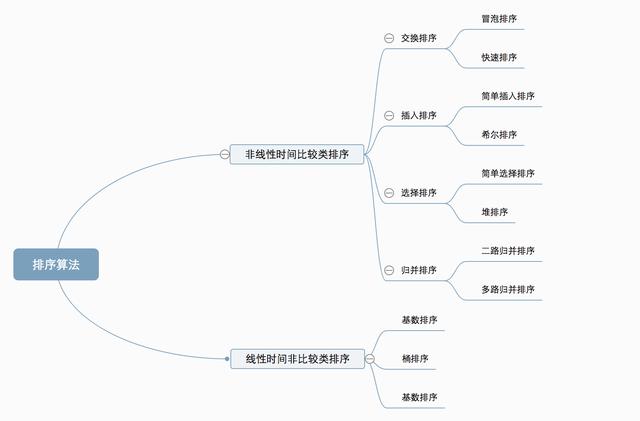
- 0、算法概述 0.1 算法分类 十种常见排序算法可以分为两大类: 非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。 线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。 0.2 算法复杂度 0.3 相关概念 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律
平凡
2018-08-08 11:05:41441906
- 我们今天讲另外一种特殊的树,“堆”(Heap)。堆这种数据结构的应用场景非常多,最经典的莫过于堆排序了。堆排序是一种原地的、时间复杂度为 O(nlog n)的排序算法。 前面我们学过快速排序,平均情况下,它的时间复杂度为 O(nlog n)。尽管这两种排序算法的时间复杂度都是 O(nlog n),甚至堆排序比快速排序的时间复杂度还要稳定,但是,在实际的软件开发中,快速排序的性能要比堆排序好,这是为什么呢? 如何理解“堆”? 前面我们提到,堆是一种特殊的树。我们现在就来看看,什么样的树才是堆。我罗列了两点要求,只要满足这两点,它就是一个堆。 堆是一个完全二叉树; 堆中每一个节点的值都必须大于
- 2020-02-13 14:50:47257223
- 一致性哈希算法是分布式系统中常用的算法,为什么要用这个算法? 比如:一个分布式存储系统,要将数据存储到具体的节点(服务器)上, 在服务器数量不发生改变的情况下,如果采用普通的hash再对服务器总数量取模的方法(如key%服务器总数量),如果期间有服务器宕机了或者需要增加服务器,问题就出来了。 同一个key经过hash之后,再与服务器总数量取模的结果跟之前的结果会不一样,这就导致了之前保存数据的丢失。因此,引入了一致性Hash(Consistent Hashing)分布算法 把数据用hash函数(如md5,sha1),映射到一个圆环上,如上图所示,数据在存储时,先根据hash算法算出key的h
- 2020-02-13 18:04:35284030
- https://www.jianshu.com/p/df71c71cdc57
- 2020-02-13 18:29:38149000